261.0
#version 310 es
precision mediump float;
layout(local_size_x = 4, local_size_y = 8) in;
layout(rgba32f, binding = 0) uniform mediump readonly image2D img_input;
layout(rgba32f, binding = 1) uniform mediump writeonly image2D img_output;
void main() {
ivec2 start_coords = ivec2(gl_GlobalInvocationID.xy) * ivec2(1,1);
highp vec4 x, y, z;
x = imageLoad(img_input, start_coords + ivec2(0,0));
y = imageLoad(img_input, start_coords + ivec2(1,0));
z = imageLoad(img_input, start_coords + ivec2(2,0));
highp vec4 r0 = vec4(
dot(x.xyzw, y.xyzw),
dot(x.xyzw, y.yxwz),
dot(x.xyzw, y.zwxy),
dot(x.xyzw, y.wzyx)
);
highp vec4 r1 = vec4(
dot(x.xyzw, z.xyzw),
dot(x.xyzw, z.yxwz),
dot(x.xyzw, z.zwxy),
dot(x.xyzw, z.wzyx)
);
highp vec4 r2 = vec4(
dot(y.xyzw, z.xyzw),
dot(y.xyzw, z.yxwz),
dot(y.xyzw, z.zwxy),
dot(y.xyzw, z.wzyx)
);
highp vec4 r3 = vec4(
dot(r0.xyzw, z.xyzw) / 4.,
dot(r0.xyzw, z.yxwz) / 4.,
dot(r0.xyzw, z.zwxy) / 4.,
dot(r0.xyzw, z.wzyx) / 4.
);
highp vec4 s0 = vec4(
dot(x.xyzw, x.xyzw),
dot(x.xyzw, x.yxwz),
dot(x.xyzw, x.zwxy),
dot(x.xyzw, x.wzyx)
);
highp vec4 s1 = vec4(
dot(y.xyzw, y.xyzw),
dot(y.xyzw, y.yxwz),
dot(y.xyzw, y.zwxy),
dot(y.xyzw, y.wzyx)
);
highp vec4 s2 = vec4(
dot(z.xyzw, z.xyzw),
dot(z.xyzw, z.yxwz),
dot(z.xyzw, z.zwxy),
dot(z.xyzw, z.wzyx)
);
highp vec4 c0 = vec4(
dot(s0.xyzw, x.xyzw) / 4.,
dot(s0.xyzw, x.yxwz) / 4.,
dot(s0.xyzw, x.zwxy) / 4.,
dot(s0.xyzw, x.wzyx) / 4.
);
highp vec4 s0y = vec4(
dot(s0.xyzw, y.xyzw) / 4.,
dot(s0.xyzw, y.yxwz) / 4.,
dot(s0.xyzw, y.zwxy) / 4.,
dot(s0.xyzw, y.wzyx) / 4.
);
highp vec4 s0z = vec4(
dot(s0.xyzw, z.xyzw) / 4.,
dot(s0.xyzw, z.yxwz) / 4.,
dot(s0.xyzw, z.zwxy) / 4.,
dot(s0.xyzw, z.wzyx) / 4.
);
highp vec4 c1 = vec4(
dot(s1.xyzw, y.xyzw) / 4.,
dot(s1.xyzw, y.yxwz) / 4.,
dot(s1.xyzw, y.zwxy) / 4.,
dot(s1.xyzw, y.wzyx) / 4.
);
highp vec4 s1x = vec4(
dot(s1.xyzw, x.xyzw) / 4.,
dot(s1.xyzw, x.yxwz) / 4.,
dot(s1.xyzw, x.zwxy) / 4.,
dot(s1.xyzw, x.wzyx) / 4.
);
highp vec4 s1z = vec4(
dot(s1.xyzw, z.xyzw) / 4.,
dot(s1.xyzw, z.yxwz) / 4.,
dot(s1.xyzw, z.zwxy) / 4.,
dot(s1.xyzw, z.wzyx) / 4.
);
highp vec4 c2 = vec4(
dot(s2.xyzw, z.xyzw) / 4.,
dot(s2.xyzw, z.yxwz) / 4.,
dot(s2.xyzw, z.zwxy) / 4.,
dot(s2.xyzw, z.wzyx) / 4.
);
highp vec4 s2x = vec4(
dot(s2.xyzw, x.xyzw) / 4.,
dot(s2.xyzw, x.yxwz) / 4.,
dot(s2.xyzw, x.zwxy) / 4.,
dot(s2.xyzw, x.wzyx) / 4.
);
highp vec4 s2y = vec4(
dot(s2.xyzw, y.xyzw) / 4.,
dot(s2.xyzw, y.yxwz) / 4.,
dot(s2.xyzw, y.zwxy) / 4.,
dot(s2.xyzw, y.wzyx) / 4.
);
r0.x += 5.; // optimizer correction
imageStore(img_output, ivec2(gl_GlobalInvocationID.xy),
r0 + r1 + r2 + r3 + s0 + s1 + s2 + c0 + c1 + c2 +
s0y+ s0z+ s1x+ s1z+ s2x+ s2y);
}
(24.24173074040384, 5668.957178202975)
FMAs: 84.47% (261 / 309)
clause_0:
ds(0) nbb attr ncph next_attr dwb(0)
{
*NOP t0
+IADD.s32 t1, r60, 0x00000002 /* 0.000000 */
*MKVEC.v2i16 t0, t1, r61
+LD_ATTR_TEX.f32.v4 t1, t, #0.x, #0.x, @r3
}
clause_3:
ds(0) nbb attr ncph next_attr dwb(0)
{
*FMA.f32 t0, r6, r3, #0.neg
+FADD.f32 t1, r4, r4
*FMA.f32 r0:t0, r5, t1, t0
+NOP t1
*MKVEC.v2i16 r2:t0, r60, r61
+LD_ATTR_TEX.f32.v4 t1, t, #0.x, #0.x, @r7
}
clause_6:
ds(0) nbb attr ncph dwb(0)
{
*FMA.f32 t0, r10, r7, #0.neg
+FADD.f32 t1, r8, r8
*FMA.f32 r11:t0, r9, t1, t0
+FADD.f32 t1, r9, r9
*FMA.f32 t0, r10, t1, #0.neg
+FADD.f32 t1, r7, r7
*FMA.f32 r12:t0, r8, t1, t0
+NOP t1
*NOP t0
+IADD.s32 t1, r60, 0x00000001 /* 0.000000 */
*MKVEC.v2i16 t0, t1, r61
+LD_ATTR_TEX.f32.v4 t1, t, #0.x, #0.x, @r13
}
clause_11:
ds(0) nbb ncph
{
*FMA.f32 r1:t0, r16, r13, #0.neg
+NOP t1
*NOP t0
+FADD.f32 r17:t1, r14, r14
}
clause_13:
ds(0) nbb ncph
{
*FMA.f32 r1:t0, r15, r17, r1
+FADD.f32 t1, r15, r15
*FMA.f32 t0, r16, t1, #0.neg
+FADD.f32 t1, r13, r13
*FMA.f32 r17:t0, r14, t1, t0
+NOP t1
*FMA.f32 t0, r6, r4, #0.neg
+NOP t1
*FMA.f32 t0, r5, r3, t0
+NOP t1
*FMA.f32 r18:t0, r6, r4, t0
+NOP t1
*FMA.f32 r0:t0, r6, r3, r0
+NOP t1
*FMA.f32 r18:t0, r5, r3, r18
+NOP t1
}
clause_19:
ds(0) nbb ncph
{
*FMA.f32 r19:t0, r6, r6, #0.neg
+NOP t1
*FMA.f32 t0, r0, r13, #0.neg
+NOP t1
*FMA.f32 r20:t0, r18, r14, t0
+NOP t1
*FMA.f32 r19:t0, r5, r5, r19
+FADD.f32 r21:t1, r5, r5
*FMA.f32 t0, r6, t1, #0.neg
+FADD.f32 r23:t1, r3, r3
*FMA.f32 r22:t0, r4, t1, t0
+NOP t1
*FMA.f32 r19:t0, r4, r4, r19
+NOP t1
*FMA.f32 r24:t0, r0, r7, #0.neg
+NOP t1
}
clause_25:
ds(0) nbb ncph
{
*FMA.f32 r24:t0, r18, r8, r24
+NOP t1
*FMA.f32 r20:t0, r22, r15, r20
+NOP t1
*FMA.f32 r19:t0, r3, r3, r19
+NOP t1
*FMA.f32 r24:t0, r22, r9, r24
+NOP t1
*FMA.f32 r20:t0, r19, r16, r20
+NOP t1
*FMA.f32 t0, r19, r10, r24
+NOP t1
*NOP t0
+FADD.f32 r20:t1, t0, r20
*FMA.f32 r24:t0, r10, r8, #0.neg
+NOP t1
}
clause_31:
ds(0) nbb ncph
{
*FMA.f32 t0, r9, r7, r24
+NOP t1
*FMA.f32 r24:t0, r10, r8, t0
+NOP t1
*FMA.f32 r11:t0, r10, r7, r11
+NOP t1
*FMA.f32 r24:t0, r9, r7, r24
+NOP t1
*FMA.f32 t0, r10, r10, #0.neg
+NOP t1
*FMA.f32 r25:t0, r9, r9, t0
+NOP t1
*FMA.f32 t0, r11, r3, #0.neg
+NOP t1
*FMA.f32 r26:t0, r24, r4, t0
+NOP t1
}
clause_37:
ds(0) nbb ncph
{
*FMA.f32 r25:t0, r8, r8, r25
+NOP t1
*FMA.f32 t0, r11, r13, #0.neg
+NOP t1
*FMA.f32 r27:t0, r24, r14, t0
+NOP t1
*FMA.f32 r26:t0, r12, r5, r26
+NOP t1
*FMA.f32 r25:t0, r7, r7, r25
+NOP t1
*FMA.f32 r27:t0, r12, r15, r27
+NOP t1
*FMA.f32 r26:t0, r25, r6, r26
+NOP t1
*FMA.f32 r27:t0, r25, r16, r27
+NOP t1
}
clause_43:
ds(0) nbb ncph
{
*NOP t0
+FADD.f32 r26:t1, r27, r26
*FMA.f32 t0, r0, r14, #0.neg
+NOP t1
*FMA.f32 r27:t0, r18, r13, t0
+NOP t1
*FMA.f32 t0, r0, r8, #0.neg
+NOP t1
*FMA.f32 r28:t0, r18, r7, t0
+NOP t1
*FMA.f32 r27:t0, r22, r16, r27
+NOP t1
*FMA.f32 r28:t0, r22, r10, r28
+NOP t1
*FMA.f32 r27:t0, r19, r15, r27
+NOP t1
}
clause_49:
ds(0) nbb ncph
{
*FMA.f32 t0, r19, r9, r28
+NOP t1
*NOP t0
+FADD.f32 r27:t1, t0, r27
*FMA.f32 t0, r16, r14, #0.neg
+NOP t1
*FMA.f32 t0, r15, r13, t0
+NOP t1
*FMA.f32 r28:t0, r16, r14, t0
+NOP t1
*FMA.f32 r1:t0, r16, r13, r1
+NOP t1
*FMA.f32 r28:t0, r15, r13, r28
+NOP t1
*FMA.f32 r29:t0, r16, r16, #0.neg
+NOP t1
}
clause_55:
ds(0) nbb ncph
{
*FMA.f32 r29:t0, r15, r15, r29
+NOP t1
*FMA.f32 t0, r11, r7, #0.neg
+NOP t1
*FMA.f32 r30:t0, r24, r8, t0
+NOP t1
*FMA.f32 t0, r1, r7, #0.neg
+NOP t1
*FMA.f32 r31:t0, r28, r8, t0
+NOP t1
*FMA.f32 r29:t0, r14, r14, r29
+NOP t1
*FMA.f32 t0, r11, r8, #0.neg
+NOP t1
*FMA.f32 r32:t0, r24, r7, t0
+NOP t1
}
clause_61:
ds(0) nbb ncph
{
*FMA.f32 t0, r1, r8, #0.neg
+NOP t1
*FMA.f32 r33:t0, r28, r7, t0
+NOP t1
*FMA.f32 r30:t0, r12, r9, r30
+NOP t1
*FMA.f32 r31:t0, r17, r9, r31
+NOP t1
*FMA.f32 r29:t0, r13, r13, r29
+NOP t1
*FMA.f32 r32:t0, r12, r10, r32
+NOP t1
*FMA.f32 r33:t0, r17, r10, r33
+NOP t1
*FMA.f32 r34:t0, r11, r9, #0.neg
+NOP t1
}
clause_67:
ds(0) nbb ncph
{
*FMA.f32 r34:t0, r24, r10, r34
+NOP t1
*FMA.f32 t0, r0, r9, #0.neg
+NOP t1
*FMA.f32 r35:t0, r18, r10, t0
+NOP t1
*FMA.f32 t0, r1, r9, #0.neg
+NOP t1
*FMA.f32 r36:t0, r28, r10, t0
+NOP t1
*FMA.f32 r30:t0, r25, r10, r30
+NOP t1
*FMA.f32 r31:t0, r29, r10, r31
+NOP t1
*FMA.f32 r37:t0, r10, r13, #0.neg
+NOP t1
}
clause_73:
ds(0) nbb ncph
{
*FMA.f32 r38:t0, r10, r14, #0.neg
+NOP t1
*FMA.f32 r39:t0, r11, r10, #0.neg
+NOP t1
*FMA.f32 r40:t0, r10, r15, #0.neg
+NOP t1
*FMA.f32 r41:t0, r10, r16, #0.neg
+NOP t1
*FMA.f32 r42:t0, r0, r10, #0.neg
+NOP t1
*FMA.f32 r43:t0, r1, r10, #0.neg
+NOP t1
*FMA.f32 r44:t0, r10, r3, #0.neg
+NOP t1
*FMA.f32 r45:t0, r10, r4, #0.neg
+NOP t1
}
clause_79:
ds(0) nbb ncph
{
*FMA.f32 r46:t0, r10, r5, #0.neg
+NOP t1
*FMA.f32 r10:t0, r10, r6, #0.neg
+NOP t1
*FMA.f32 r37:t0, r9, r14, r37
+NOP t1
*FMA.f32 r38:t0, r9, r13, r38
+NOP t1
*FMA.f32 r39:t0, r24, r9, r39
+NOP t1
*FMA.f32 r40:t0, r9, r16, r40
+NOP t1
*FMA.f32 r41:t0, r9, r15, r41
+NOP t1
*FMA.f32 r42:t0, r18, r9, r42
+NOP t1
}
clause_85:
ds(0) nbb ncph
{
*FMA.f32 r43:t0, r28, r9, r43
+NOP t1
*FMA.f32 r44:t0, r9, r4, r44
+NOP t1
*FMA.f32 r45:t0, r9, r3, r45
+NOP t1
*FMA.f32 r46:t0, r9, r6, r46
+NOP t1
*FMA.f32 r10:t0, r9, r5, r10
+NOP t1
*FMA.f32 r32:t0, r25, r9, r32
+NOP t1
*FMA.f32 r9:t0, r29, r9, r33
+NOP t1
*FMA.f32 r33:t0, r11, r4, #0.neg
+NOP t1
}
clause_91:
ds(0) nbb ncph
{
*FMA.f32 r33:t0, r24, r3, r33
+NOP t1
*FMA.f32 t0, r11, r14, #0.neg
+NOP t1
*FMA.f32 r47:t0, r24, r13, t0
+NOP t1
*FMA.f32 r33:t0, r12, r6, r33
+NOP t1
*FMA.f32 r47:t0, r12, r16, r47
+NOP t1
*FMA.f32 r33:t0, r25, r5, r33
+NOP t1
*FMA.f32 t0, r25, r15, r47
+NOP t1
*NOP t0
+FADD.f32 r33:t1, t0, r33
}
clause_97:
ds(0) nbb ncph
{
*FMA.f32 t0, r1, r13, #0.neg
+NOP t1
*FMA.f32 r47:t0, r28, r14, t0
+NOP t1
*FMA.f32 t0, r1, r14, #0.neg
+NOP t1
*FMA.f32 r48:t0, r28, r13, t0
+NOP t1
*FMA.f32 r37:t0, r8, r15, r37
+NOP t1
*FMA.f32 r47:t0, r17, r15, r47
+NOP t1
*FMA.f32 r38:t0, r8, r16, r38
+NOP t1
*FMA.f32 r48:t0, r17, r16, r48
+NOP t1
}
clause_103:
ds(0) nbb ncph
{
*FMA.f32 t0, r11, r15, #0.neg
+NOP t1
*FMA.f32 r49:t0, r24, r16, t0
+NOP t1
*FMA.f32 t0, r0, r15, #0.neg
+NOP t1
*FMA.f32 r50:t0, r18, r16, t0
+NOP t1
*FMA.f32 t0, r1, r15, #0.neg
+NOP t1
*FMA.f32 r51:t0, r28, r16, t0
+NOP t1
*FMA.f32 r37:t0, r7, r16, r37
+NOP t1
*FMA.f32 r47:t0, r29, r16, r47
+NOP t1
}
clause_109:
ds(0) nbb ncph
{
*FMA.f32 r52:t0, r11, r16, #0.neg
+NOP t1
*FMA.f32 r53:t0, r0, r16, #0.neg
+NOP t1
*FMA.f32 r54:t0, r16, r3, #0.neg
+NOP t1
*FMA.f32 r55:t0, r16, r4, #0.neg
+NOP t1
*FMA.f32 r56:t0, r16, r5, #0.neg
+NOP t1
*FMA.f32 r57:t0, r16, r6, #0.neg
+NOP t1
*FMA.f32 r16:t0, r1, r16, #0.neg
+NOP t1
*FMA.f32 r52:t0, r24, r15, r52
+NOP t1
}
clause_115:
ds(0) nbb ncph
{
*FMA.f32 r53:t0, r18, r15, r53
+NOP t1
*FMA.f32 r54:t0, r15, r4, r54
+NOP t1
*FMA.f32 r55:t0, r15, r3, r55
+NOP t1
*FMA.f32 r56:t0, r15, r6, r56
+NOP t1
*FMA.f32 r57:t0, r15, r5, r57
+NOP t1
*FMA.f32 r16:t0, r28, r15, r16
+NOP t1
*FMA.f32 r38:t0, r7, r15, r38
+NOP t1
*FMA.f32 r15:t0, r29, r15, r48
+NOP t1
}
clause_121:
ds(0) nbb ncph
{
*NOP t0
+FADD.f32 t1, r12, r17
*FMA.f32 r21:t0, r6, r21, t1
+NOP t1
*FMA.f32 t0, r11, r5, #0.neg
+NOP t1
*FMA.f32 r48:t0, r24, r6, t0
+NOP t1
*FMA.f32 t0, r11, r6, #0.neg
+NOP t1
*FMA.f32 r58:t0, r24, r5, t0
+NOP t1
*FMA.f32 r48:t0, r12, r3, r48
+NOP t1
*FMA.f32 r49:t0, r12, r13, r49
+NOP t1
}
clause_127:
ds(0) nbb ncph
{
*FMA.f32 r39:t0, r12, r8, r39
+NOP t1
*FMA.f32 r58:t0, r12, r4, r58
+NOP t1
*FMA.f32 r52:t0, r12, r14, r52
+NOP t1
*FMA.f32 r12:t0, r12, r7, r34
+NOP t1
*FMA.f32 r34:t0, r22, r13, r50
+NOP t1
*FMA.f32 r35:t0, r22, r7, r35
+NOP t1
*FMA.f32 r34:t0, r19, r14, r34
+NOP t1
*FMA.f32 r35:t0, r19, r8, r35
+NOP t1
}
clause_133:
ds(0) nbb ncph
{
*NOP t0
+FADD.f32 r34:t1, r35, r34
*FMA.f32 r35:t0, r25, r4, r48
+NOP t1
*FMA.f32 r48:t0, r25, r14, r49
+NOP t1
*FMA.f32 r40:t0, r8, r13, r40
+NOP t1
*NOP t0
+FADD.f32 r35:t1, r48, r35
*FMA.f32 r48:t0, r17, r13, r51
+NOP t1
*FMA.f32 r49:t0, r22, r14, r53
+NOP t1
*FMA.f32 r41:t0, r8, r14, r41
+NOP t1
}
clause_139:
ds(0) nbb ncph
{
*FMA.f32 r50:t0, r14, r5, r54
+NOP t1
*FMA.f32 r51:t0, r14, r6, r55
+NOP t1
*FMA.f32 r53:t0, r14, r3, r56
+NOP t1
*FMA.f32 r54:t0, r14, r4, r57
+NOP t1
*FMA.f32 r16:t0, r17, r14, r16
+NOP t1
*FMA.f32 r40:t0, r7, r14, r40
+NOP t1
*FMA.f32 r14:t0, r29, r14, r48
+NOP t1
*FMA.f32 r48:t0, r0, r3, #0.neg
+NOP t1
}
clause_145:
ds(0) nbb ncph
{
*FMA.f32 r48:t0, r18, r4, r48
+NOP t1
*FMA.f32 t0, r0, r4, #0.neg
+NOP t1
*FMA.f32 r55:t0, r18, r3, t0
+NOP t1
*FMA.f32 t0, r0, r5, #0.neg
+NOP t1
*FMA.f32 r56:t0, r18, r6, t0
+NOP t1
*FMA.f32 t0, r0, r6, #0.neg
+NOP t1
*FMA.f32 r57:t0, r18, r5, t0
+NOP t1
*FMA.f32 r42:t0, r22, r8, r42
+NOP t1
}
clause_151:
ds(0) nbb ncph
{
*FMA.f32 r48:t0, r22, r5, r48
+NOP t1
*FMA.f32 r55:t0, r22, r6, r55
+NOP t1
*FMA.f32 r56:t0, r22, r3, r56
+NOP t1
*FMA.f32 r22:t0, r22, r4, r57
+NOP t1
*FMA.f32 t0, r1, r3, #0.neg
+NOP t1
*FMA.f32 r57:t0, r28, r4, t0
+NOP t1
*FMA.f32 t0, r1, r4, #0.neg
+NOP t1
*FMA.f32 r59:t0, r28, r3, t0
+NOP t1
}
clause_157:
ds(0) nbb ncph
{
*FMA.f32 t0, r1, r5, #0.neg
+NOP t1
*FMA.f32 r60:t0, r28, r6, t0
+NOP t1
*FMA.f32 t0, r1, r6, #0.neg
+NOP t1
*FMA.f32 r61:t0, r28, r5, t0
+NOP t1
*FMA.f32 r43:t0, r17, r8, r43
+NOP t1
*FMA.f32 r57:t0, r17, r5, r57
+NOP t1
*FMA.f32 r59:t0, r17, r6, r59
+NOP t1
*FMA.f32 r36:t0, r17, r7, r36
+NOP t1
}
clause_163:
ds(0) nbb ncph
{
*FMA.f32 r60:t0, r17, r3, r60
+NOP t1
*FMA.f32 r17:t0, r17, r4, r61
+NOP t1
*FMA.f32 r49:t0, r19, r13, r49
+NOP t1
*FMA.f32 r42:t0, r19, r7, r42
+NOP t1
*FMA.f32 r44:t0, r8, r5, r44
+NOP t1
*FMA.f32 r45:t0, r8, r6, r45
+NOP t1
*FMA.f32 r46:t0, r8, r3, r46
+NOP t1
*FMA.f32 r10:t0, r8, r4, r10
+NOP t1
}
clause_169:
ds(0) nbb ncph
{
*FMA.f32 r41:t0, r7, r13, r41
+NOP t1
*FMA.f32 r44:t0, r7, r6, r44
+NOP t1
*FMA.f32 r45:t0, r7, r5, r45
+NOP t1
*FMA.f32 r46:t0, r7, r4, r46
+NOP t1
*FMA.f32 r39:t0, r25, r7, r39
+NOP t1
*FMA.f32 r10:t0, r7, r3, r10
+NOP t1
*FMA.f32 r7:t0, r29, r7, r43
+NOP t1
*FMA.f32 r43:t0, r25, r3, r58
+NOP t1
}
clause_175:
ds(0) nbb ncph
{
*NOP t0
+FADD.f32 r42:t1, r42, r49
*FMA.f32 t0, r25, r13, r52
+NOP t1
*NOP t0
+FADD.f32 r43:t1, t0, r43
*FMA.f32 r49:t0, r13, r6, r50
+NOP t1
*FMA.f32 r50:t0, r13, r5, r51
+NOP t1
*FMA.f32 r51:t0, r13, r4, r53
+NOP t1
*FMA.f32 r52:t0, r13, r3, r54
+NOP t1
*FMA.f32 r13:t0, r29, r13, r16
+NOP t1
}
clause_181:
ds(0) nbb ncph
{
*FMA.f32 r0:t0, r30, 0x3e800000 /* 0.250000 */, r0
+NOP t1
*NOP t0
+FADD.f32 r1:t1, r11, r1
*FMA.f32 t0, r37, r3, #0.neg
+NOP t1
*FMA.f32 t0, r38, r4, t0
+NOP t1
*FMA.f32 t0, r40, r5, t0
+NOP t1
*FMA.f32 r11:t0, r41, r6, t0
+NOP t1
*NOP t0
+FADD.f32 r16:t1, r31, r20
*NOP t0
+FADD.f32 r20:t1, r47, r26
}
clause_187:
ds(0) nbb ncph
{
*FMA.f32 t0, r37, r4, #0.neg
+NOP t1
*FMA.f32 t0, r38, r3, t0
+NOP t1
*FMA.f32 r26:t0, r40, r6, t0
+NOP t1
*FMA.f32 r31:t0, r37, r5, #0.neg
+FADD.f32 r30:t1, r37, r44
*FMA.f32 r37:t0, r37, r6, #0.neg
+NOP t1
*FMA.f32 r31:t0, r38, r6, r31
+NOP t1
*FMA.f32 r44:t0, r29, r6, r57
+NOP t1
*FMA.f32 r6:t0, r19, r6, r48
+NOP t1
}
clause_193:
ds(0) nbb ncph
{
*FMA.f32 r18:t0, r32, 0x3e800000 /* 0.250000 */, r18
+NOP t1
*FMA.f32 r26:t0, r41, r5, r26
+NOP t1
*NOP t0
+FADD.f32 r24:t1, r24, r28
*FMA.f32 r28:t0, r38, r5, r37
+NOP t1
*NOP t0
+FADD.f32 r9:t1, r9, r27
*FMA.f32 r27:t0, r29, r5, r59
+NOP t1
*FMA.f32 r5:t0, r19, r5, r55
+NOP t1
*FMA.f32 r21:t0, r4, r23, r21
+NOP t1
}
clause_199:
ds(0) nbb ncph
{
*FMA.f32 r23:t0, r29, r8, r36
+NOP t1
*FMA.f32 r8:t0, r25, r8, r12
+NOP t1
*FMA.f32 t0, r40, r3, r31
+NOP t1
*FMA.f32 t0, r41, r4, t0
+NOP t1
*FMA.f32 r12:t0, t0, 0x3e800000 /* 0.250000 */, r51
+NOP t1
*FMA.f32 r28:t0, r40, r4, r28
+NOP t1
*NOP t0
+FADD.f32 r15:t1, r15, r33
*FMA.f32 r33:t0, r29, r4, r60
+NOP t1
}
clause_205:
ds(0) nbb ncph
{
*FMA.f32 r4:t0, r19, r4, r56
+NOP t1
*NOP t0
+FADD.f32 r23:t1, r23, r34
*FMA.f32 r34:t0, r39, 0x3e800000 /* 0.250000 */, r19
+NOP t1
*FMA.f32 r19:t0, r19, r3, r22
+NOP t1
*FMA.f32 r22:t0, r41, r3, r28
+NOP t1
*FMA.f32 r3:t0, r29, r3, r17
+NOP t1
*FMA.f32 r22:t0, r22, 0x3e800000 /* 0.250000 */, r52
+NOP t1
*FMA.f32 r8:t0, r8, 0x3e800000 /* 0.250000 */, r21
+NOP t1
}
clause_211:
ds(0) nbb ncph
{
*NOP t0
+FADD.f32 r0:t1, r1, r0
*FMA.f32 t0, r11, 0x3e800000 /* 0.250000 */, r49
+FADD.f32 r1:t1, r30, t
*NOP t0
+FADD.f32 r11:t1, r44, r16
*NOP t0
+FADD.f32 r0:t1, r1, r0
*FADD.f32 t0, r6, r20
+FADD.f32 t1, t, r11
*FMA.f32 r0:t0, 0x3e800000 /* 0.250000 */, t1, r0
+NOP t1
*NOP t0
+FADD.f32 r32:t1, r38, r45
*NOP t0
+FADD.f32 r16:t1, r24, r18
}
clause_217:
ds(0) nbb ncph next_attr
{
*FMA.f32 t0, r26, 0x3e800000 /* 0.250000 */, r50
+FADD.f32 r18:t1, r32, t
*NOP t0
+FADD.f32 r9:t1, r27, r9
*NOP t0
+FADD.f32 r6:t1, r18, r16
*FADD.f32 t0, r5, r15
+FADD.f32 t1, t, r9
*FMA.f32 r1:t0, 0x3e800000 /* 0.250000 */, t1, r6
+NOP t1
*NOP t0
+FADD.f32 r31:t1, r40, r46
*NOP t0
+FADD.f32 r14:t1, r14, r35
*NOP t0
+FADD.f32 r15:t1, r33, r23
}
clause_223:
ds(0) nbb attr ncph next_store dwb(0)
{
*FADD.f32 t0, r31, r12
+FADD.f32 r8:t1, t, r8
*FADD.f32 t0, r4, r14
+FADD.f32 t1, t, r15
*FMA.f32 r4:t0, 0x3e800000 /* 0.250000 */, t1, r8
+NOP t1
*NOP t0
+FADD.f32 t1, r7, r42
*NOP t0
+FADD.f32 r3:t1, r3, t1
*FADD.f32 t0, r13, r43
+FADD.f32 t1, r19, t
*NOP t0
+FADD.f32 r3:t1, t1, r3
*DTSEL_IMM.attribute_1 t0, r2
+LEA_ATTR_TEX.f32 t1, t, 0x00000000 /* 0.000000 */, 0x00000001 /* 0.000000 */, @r5
}
clause_230:
ds(0) eos store
{
*NOP t0
+FADD.f32 r17:t1, r25, r29
*FADD.f32 t0, r41, 0x40a00000 /* 5.000000 */
+FADD.f32 r10:t1, t, r10
*NOP t0
+FADD.f32 t1, r17, r34
*FADD.f32 t0, r10, r22
+FADD.f32 t1, t, t1
*FMA.f32 t0, 0x3e800000 /* 0.250000 */, r3, t1
+MOV.i32 r8:t1, t
*MOV.i32 r9:t0, r4
+MOV.i32 r10:t1, r1
*NOP t0
+MOV.i32 r11:t1, r0
*NOP t0
+ST_CVT.v4 t1, r5, r6, r7, @r8
}
shader21995 - MESA_SHADER_COMPUTE shader: 0 inst, 0 bundles, 0 quadwords, 0 registers, 4 threads, 0 loops, 0:0 spills:fills
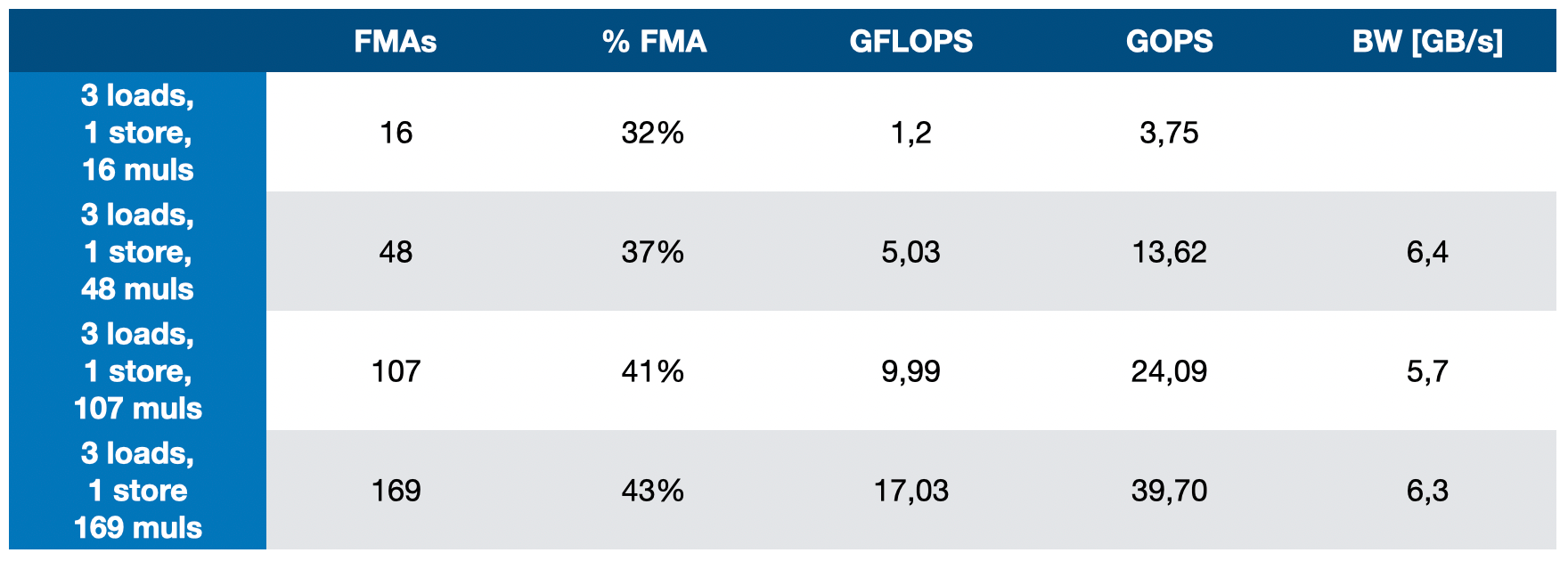
_files/figure-html/cell-3-output-1.png)
_files/figure-html/cell-5-output-1.png)
_files/figure-html/cell-7-output-1.png)
_files/figure-html/cell-9-output-2.png)
_files/figure-html/cell-11-output-1.png)
_files/figure-html/cell-13-output-2.png)