WhisperSpeech
![]()
If you have questions or you want to help you can find us in the #audio-generation channel on the LAION Discord server.
An Open Source text-to-speech system built by inverting Whisper. Previously known as spear-tts-pytorch.
We want this model to be like Stable Diffusion but for speech – both powerful and easily customizable.
We are working only with properly licensed speech recordings and all the code is Open Source so the model will be always safe to use for commercial applications.
Currently the models are trained on the English LibreLight dataset. In the next release we want to target multiple languages (Whisper and EnCodec are both multilanguage).
Sample of the synthesized voice:
https://github.com/collabora/WhisperSpeech/assets/107984/aa5a1e7e-dc94-481f-8863-b022c7fd7434
Progress update [2024-01-29]
We successfully trained a tiny S2A model on an en+pl+fr dataset and it can do voice cloning in French:
https://github.com/collabora/WhisperSpeech/assets/107984/267f2602-7eec-4646-a43b-059ff91b574e
https://github.com/collabora/WhisperSpeech/assets/107984/fbf08e8e-0f9a-4b0d-ab5e-747ffba2ccb9
We were able to do this with frozen semantic tokens that were only trained on English and Polish. This supports the idea that we will be able to train a single semantic token model to support all the languages in the world. Quite likely even ones that are not currently well supported by the Whisper model. Stay tuned for more updates on this front. :)
Progress update [2024-01-18]
We spend the last week optimizing inference performance. We integrated torch.compile, added kv-caching and tuned some of the layers – we are now working over 12x faster than real-time on a consumer 4090!
We can mix languages in a single sentence (here the highlighted English project names are seamlessly mixed into Polish speech):
To jest pierwszy test wielojęzycznego
Whisper Speechmodelu zamieniającego tekst na mowę, któryCollaboraiLaionnauczyli na superkomputerzeJewels.
https://github.com/collabora/WhisperSpeech/assets/107984/d7092ef1-9df7-40e3-a07e-fdc7a090ae9e
We also added an easy way to test voice-cloning. Here is a sample voice cloned from a famous speech by Winston Churchill (the radio static is a feature, not a bug ;) – it is part of the reference recording):
https://github.com/collabora/WhisperSpeech/assets/107984/bd28110b-31fb-4d61-83f6-c997f560bc26
You can test all of these on Colab (we optimized the dependencies so now it takes less than 30 seconds to install). A Huggingface Space is coming soon.
Progress update [2024-01-10]
We’ve pushed a new SD S2A model that is a lot faster while still generating high-quality speech. We’ve also added an example of voice cloning based on a reference audio file.
As always, you can check out our Colab to try it yourself!
Progress update [2023-12-10]
Another trio of models, this time they support multiple languages (English and Polish). Here are two new samples for a sneak peek. You can check out our Colab to try it yourself!
English speech, female voice (transferred from a Polish language dataset):
https://github.com/collabora/WhisperSpeech/assets/107984/aa5a1e7e-dc94-481f-8863-b022c7fd7434
A Polish sample, male voice:
https://github.com/collabora/WhisperSpeech/assets/107984/4da14b03-33f9-4e2d-be42-f0fcf1d4a6ec
Downloads
We encourage you to start with the Google Colab link above or run the provided notebook locally. If you want to download manually or train the models from scratch then both the WhisperSpeech pre-trained models as well as the converted datasets are available on HuggingFace.
Roadmap
Architecture
The general architecture is similar to AudioLM, SPEAR TTS from Google and MusicGen from Meta. We avoided the NIH syndrome and built it on top of powerful Open Source models: Whisper from OpenAI to generate semantic tokens and perform transcription, EnCodec from Meta for acoustic modeling and Vocos from Charactr Inc as the high-quality vocoder.
We gave two presentation diving deeper into WhisperSpeech. The first one talks about the challenges of large scale training:

The other one goes a bit more into the architectural choices we made:

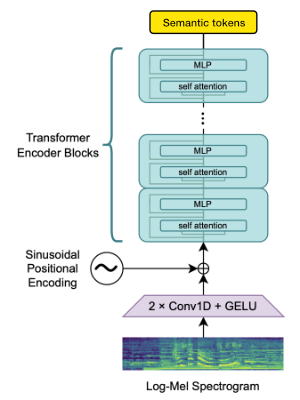
Whisper for modeling semantic tokens
We utilize the OpenAI Whisper encoder block to generate embeddings which we then quantize to get semantic tokens.
If the language is already supported by Whisper then this process requires only audio files (without ground truth transcriptions).
EnCodec for modeling acoustic tokens
We use EnCodec to model the audio waveform. Out of the box it delivers reasonable quality at 1.5kbps and we can bring this to high-quality by using Vocos – a vocoder pretrained on EnCodec tokens.

Appreciation


This work would not be possible without the generous sponsorships from:
- Collabora – code development and model training
- LAION – community building and datasets (special thanks to
- Jülich Supercomputing Centre - JUWELS Booster supercomputer
We gratefully acknowledge the Gauss Centre for Supercomputing e.V. (www.gauss-centre.eu) for funding part of this work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC), with access to compute provided via LAION cooperation on foundation models research.
We’d like to also thank individual contributors for their great help in building this model:
- inevitable-2031 (
qwerty_qweron Discord) for dataset curation
Consulting
We are available to help you with both Open Source and proprietary AI projects. You can reach us via the Collabora website or on Discord ( and
)
Citations
We rely on many amazing Open Source projects and research papers:
@article{SpearTTS,
title = {Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision},
url = {https://arxiv.org/abs/2302.03540},
author = {Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil},
publisher = {arXiv},
year = {2023},
}@article{MusicGen,
title={Simple and Controllable Music Generation},
url = {https://arxiv.org/abs/2306.05284},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
publisher={arXiv},
year={2023},
}@article{Whisper
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
publisher = {arXiv},
year = {2022},
}@article{EnCodec
title = {High Fidelity Neural Audio Compression},
url = {https://arxiv.org/abs/2210.13438},
author = {Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
publisher = {arXiv},
year = {2022},
}@article{Vocos
title={Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis},
url = {https://arxiv.org/abs/2306.00814},
author={Hubert Siuzdak},
publisher={arXiv},
year={2023},
}